
一.正则表达式的概念
1.定义
正则表达式,也称为正则表达式。(英语:正则表达式,代码中常缩写为regex、regexp或re),计算机科学的一个概念。正则表达式通常用于检索和替换符合某种模式(规则)的文本。正则表达式是一种文本模式,包括普通字符(例如,A和Z之间的字母)和特殊字符(称为“元字符”)。正则表达式使用单个字符串来描述和匹配一系列符合特定语法规则的字符串。
2.表达式列表
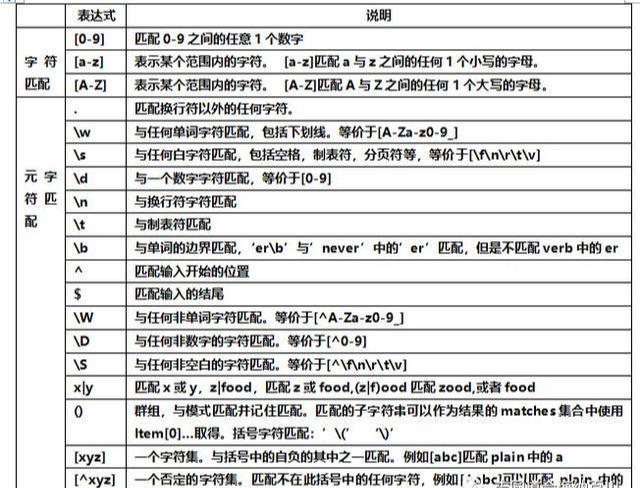

私信菜鸟007有更多教程!
3.(?ILmsux)设置分组模式。
这里的“I”、“L”、“M”、“S”、“U”、“X”不匹配任何字符串,而是代表对应于(re。我想。我是说。m,re。s,re。u,re。x)在python的re模块中。
正如您在python源代码中看到的:
I = Ignore case # Ignore case L = LOCALE #字符集本地化。为了支持多语言版本的字符集,请使用环境U = UNICODE #。当使用元字符\w,\W,\b,\B时,将遵循Unicode定义的属性M = MULTILINE #。改变“S = DOTALL # ‘ .”的行为不受限制,包括换行符X = VERBOSE #的冗余模式,正则表达式中空 white和#的注释可以忽略。正则表达式中可以同时使用六种模式,python中使用了按位OR运算符|来同时添加多个模式,比如:re.pile(“)。
4.反斜杠的使用
在一般的程序设计语言中,反斜杠“\”代表一个含义相反的字符,在反斜杠后面加一个字符可以表示特定的含义。接下来,列出了几种常见的转义字符。
因为在正则表达式的规则中,\ ‘表示转义字符,基本语法规则中也有提到,但一般情况下,\ ‘也表示转义字符,所以我们在编写代码时如果在正则表达式中使用’ \ ‘,就需要写四个’ \ ‘来表示一个真正的反斜杠字符,比如“\”\ \ \”:这里的第一个和第三个字在编程语言中用来转义,结果是\ \”,然后在正则表达式中,反过来就表示一个真正的反斜杠字符。但是在python中,我们可以忽略这个问题。只要在写出的字符串前面加个‘r’告诉编译器这个字符串是原生字符串,不要转义。例如,上一个示例中的正则表达式可以用r“\”来表示。因为加这个‘r’只是告诉python不要对这个字符串进行转义,但还是要符合正则表达式中正则表达式的规则。同样,匹配一个数字的“\d”可以写成r“\ d”。所以用python写正则表达式的时候,要养成前面写‘r’的习惯。
5.表达的应用和区别:
(1).$ {}
注意:前面的*、+、?等等。都是贪心匹配,也就是尽可能匹配,加法?数字使它成为一个惰性的匹配。
(2)字符集[] []
(3)转义符\
在正则表达式中,有许多具有特殊意义的元字符,如\d和\s等。如果要匹配正则表达式中正常的“\d”而不是“number”,需要对“\”进行转义,变成“\ \”。在python中,正则表达式和要匹配的内容都是字符串的形式,\在字符串中也有特殊的含义,需要进行转义。所以如果匹配一次“\d”,字符串就写成’ \d ‘,那么常规字符串就写成“\ \ d”,这样就太麻烦了。这时我们用r’\d ‘的概念,此时的正则化为r’\d ‘。
(4)贪婪匹配
(5)非贪婪匹配
*?随时重复,但越少越好+?重复1次或多次,但越少越好??重复0或1次,但尽量少重复{n,m}?重复n到m次,但是尽量少{n,}?重复n次或更多,但越少越好(6)。使用
是任意字符*还是0到无限长?非贪婪模式。在一起的是尽可能少的任意字符。一般不单独写。它主要用于:。*?X就是在它前面放上任意长度的字符,直到出现X。6.re函数方法总结。
7.常用函数的示例
(1)贪婪和非贪婪模式的例子
import reexample = ” & ltdiv & gttest1 & lt/div & gt;& ltdiv & gttest2 & lt/div >;”greed pattern = re . compile(” & lt;div & gt。* & lt/div >;”)not greed pattern = re . compile(” & lt;div & gt。*?& lt/div >;”)greed result = greed pattern . search(example)not greed result = not greed pattern . search(example)print(” greed result = % s ” % greed result . group())print(” not greed result = % s ” % not greed result . group())输出结果:
(2)complie()
# Describe defcompile (pattern,flags = 0):“编译正则表达式模式,返回模式对象。”#生成正则表达式模式。返回一个Regex对象return _compile(pattern,flags)#参数描述模式:正则表达式标志:用于修改正则表达式的匹配方法,也就是我们在基本语法规则中提到的六种(iLmsux)模式。例如,默认正常模式:
import repattern = re . compile(r ” \ d “)result = pattern . match(” 123 “)print(result . group())pattern = re . compile(r ” ABC d “,Re.i | re.x) “”I = ignorecase #忽略case X = VERBOSE #的冗余模式,可以忽略正则表达式中的注释” ” result = pattern . match(” ABCD “)print(result . group()):
(3)匹配()
源代码描述:
1.def match(pattern,string,flags=0):” ” “尝试在字符串的开头应用模式,返回一个match对象,如果找不到匹配,则返回None。”” ” #匹配字符串开头的模式,并返回match对象,如果没有无法匹配的对象,则返回None。return _compile(模式,标志)。匹配(字符串)2。def match(self,string,pos=0,End pos = -1):” “匹配字符串开头的零|多个字符。” ” Pass #可以指定匹配字符串的起始位置#参数说明#其他两个参数与compile()中的含义相同String: string pos to be verified:设置起始位置,default 0endpos:设置结束位置,default-1例如:
Import re result = re.match (r “a+\ d “,” aA123 “,re.i) print (result.group ()) #输出结果为aA1。只要模式匹配就视为成功,匹配成功的字符串返回pattern = re.pile (r “abcd “。re . I | re . x)result = pattern . match(” 0 ABC D5 “,1,5) print (result.group ()) #输出结果是从abcd的第一个位置到第五个位置的字符串(4)search()。
源代码描述:
1.def search(pattern,string,flags=0):” ” “扫描字符串以查找与模式的匹配,返回匹配对象,如果没有找到匹配,则返回None。”” ” #一般意义与match方法相同,区别在于搜索时匹配任意位置的整个字符串,而return _compile(pattern,flags)。搜索(字符串)2。def search(self,string,pos=0,endpos=-1):” ” “扫描字符串以查找匹配,并返回相关的匹配实例。如果字符串中没有匹配的位置,则返回none。” ” pass #你可以指定一个字符串的子串来匹配#参数与match()一致的例子:
import repattern = re.compile(r”abc d”, re.I|re.X)result = pattern.search(“0A2aBcd7″)print(result.group())# 输出结果为aBcd 在字符串中任意位置只要匹配到就返回结果pattern = re.compile(r”abc d”, re.I|re.X)matchResult = pattern.match(“0AbcD5”)searchResult = pattern.search(“0AbcD5”)print(matchResult)print(searchResult)# matchResult的结果是None# searchResult.group()的结果结果为AbcD# 因为在pattern中第一个位置是a,但是在字符串中第一个位置是0,所以match方法在这里匹配失败
免责声明:本站所有文章内容,图片,视频等均是来源于用户投稿和互联网及文摘转载整编而成,不代表本站观点,不承担相关法律责任。其著作权各归其原作者或其出版社所有。如发现本站有涉嫌抄袭侵权/违法违规的内容,侵犯到您的权益,请在线联系站长,一经查实,本站将立刻删除。