
为什么要做迁移?
由于系统版本和数据库升级,测试过程受阻。为了保证数据和系统版本的一致性,我迫切需要使用这个环境进行性能测试。所以向领导和发展请示后,这次有机会学习,特此全程记录。
使用方案:
通过工具和编码的结合,对MySQL数据库进行备份,并将备份数据库恢复到本地MySQL数据库。使用第三方工具完成数据迁移,SQL文章数量由代码统计。根据库名和表名回写结果,通过ultracompare实现比较。
使用工具:第一种迁移工具
微软SQL Server Migration Assistant for MySQL:这个工具是微软推荐的,但是会有一些问题,比如部分表数据不能完全迁移。
第二种迁移工具
Nicat Premium 12:不推荐,速度慢,容易出故障。
第三种迁移工具
Tapdata:这也是一个不错的第三方工具,但是不稳定,总内存溢出,而且是底层Ja写的。需要和客服沟通解决使用中的问题,客服响应速度也不是很理想。
比对工具
Ultracompare:比较结果使用
工具使用第一种迁移工具使用
微软SQL Server Migration Assistant for MySQL,这个工具是微软做的,真的很好用,也比较快。
从https://www.microsoft.com/en-us/download/details.aspx?. Id = 54257,下载并安装。
下面介绍如何使用这个工具,具体步骤如下:
步骤1:创建一个迁移项目。
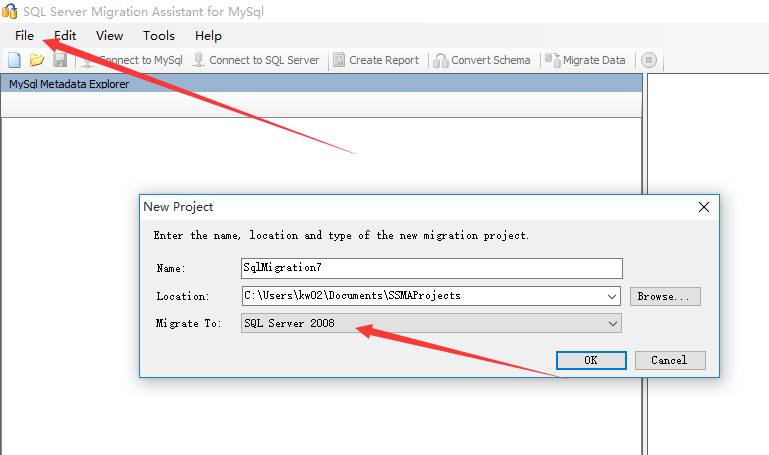

请注意,您需要选择要迁移到的SQL Server数据库的版本。目前支持:SQL Azure、SQL Server 2005、SQL Server 2008、SQL Server 2012和SQL Server 2014。根据实际需要选择要迁移到目标数据库的版本。
步骤2:连接源数据库和目标数据库。
上面是源:MySQL,下面是目标:SQL Server。
步骤3:选择要迁移的数据库以创建迁移分析报告。
该报告分析数据库中当前需要迁移的所有表结构,并生成可行性报告。
生成的报告如下:
分析需要转换多少对象、表和数据库,是否有不可转换的对象。如果有任何检查错误,将产生以下输出。
步骤4:转换模式,即数据库结构。
迁移分为两步:1 .转换数据库结构;2.迁移数据;
第5步:在源数据库中进行模式转换后,记得在目标数据库上执行同步模式操作。
否则,转换后的数据库结构将无法到达目标数据库。
单击同步后,还会有一个同步报告:
单击OK后,真正的同步操作将把您转换的结构同步到目标数据库,并创建相应的表和其他对象。同步操作完成后,将会有以下输出:
第六步:结构同步完成后,下一步就是数据迁移操作。
我们可以看到右边有几个标签页。目前选择的是类型映射,会列出源数据库和目标数据库的字段类型的映射关系。
因为不同数据库之间的数据类型还是不一样的。
点击迁移数据后,需要再次确认源数据库的密码和目标数据库的密码,然后开始真正的数据迁移。
执行后只需等待完成,还会生成数据迁移完成的报告。至此,数据迁移即可完成。
第二种迁移工具使用
Nicat Premium 12更易于操作,因为许多步骤可以是图形化的,相对简单。
具体操作步骤如下:
建立MySQL和SqlServer连接,
双击MySQL连接以建立连接。
然后选择左上角的nicat工具。
数据将自动导入。
注意:该工具不会同步约束,例如默认值。但是non 空约束可以传递给SqlServer。
第三种迁移工具
Tapdata,这个工具是永久免费的,相对来说比较好用。具体使用方法如下:
步骤1:配置MySQL连接
1.点击Tapdata云操作后台左侧菜单栏中的连接管理,然后点击右侧区域连接列表右上角的创建连接,打开连接类型选择页面,然后选择MySQL。
2.在打开的连接信息配置页面依次输入所需的配置信息。
【连接名称】:设置连接的名称,多个连接的名称不能重复。
[数据库地址]:数据库IP/主机
[结束端口]:数据库端口
[数据库名称]: tapdata数据库连接以一个db作为数据源。这里的db指的是数据库实例中的数据库,而不是mysql实例。
帐号:可以访问数据库的帐号。
[密码]:数据库帐户对应的密码。
[时间和时区]:默认使用数据库的时区;如果指定了时区,则使用指定的时区设置。
步骤2:配置SQL Server连接
3.通过第一步,在左侧菜单栏中点击连接管理,然后在右侧区域的连接列表右上角点击创建连接,打开连接类型选择页面,然后选择SQL Server。
4.在打开的连接信息配置页面中依次输入需要的配置信息,配置完成后保存测试连接。
第3步:选择同步模式—完整/增量/完整+增量。
进入Tapdata云运营后台任务管理页面,点击添加任务按钮,进入任务设置流程。
根据刚刚建立的连接,选择源和目的地。
根据数据需求,选择需要同步的库和表。如果需要修改表名,可以通过页面中的表名批量修改功能,在目的端批量设置表名。
设置上述选项后,下一步是选择同步类型。平台提供完全同步、增量同步、完全+增量同步,并设置写入方式和读取量。
如果选择全量+增量同步,Tapdata代理将在全量任务完成后自动进入增量同步状态。在这种状态下,Tapdata Agent会持续监控源端的数据变化(包括写入、更新和删除),并将这些数据变化实时写入目标端。
单击任务名称打开任务详细信息页面,您可以查看任务详细信息。
点击任务监控,弹出任务执行详细信息页面,可以查看任务进度/里程碑等具体信息。
第四步:检查数据
一般同步完成后,我习惯性的检查数据,防止踩坑。
Tapdata有三种验证模式,我经常用最快的快速计数验证,简单方便,只需要选择要验证的表,不需要设置其他复杂的参数和条件。
如果觉得不够,还可以选择表格全字段值验证。在这种情况下,除了选择要验证的表之外,还需要为每个表设置索引字段。
验证表中所有字段的值时,也支持高级验证。可以通过高级验证添加JS验证逻辑,验证源和目标的数据。
还有一种与字段值验证相关的验证方法。创建相关字段值校验时,除了选择要校验的表外,还需要为每个表设置索引字段。
以上是MySQL数据实时同步到SQL Server的操作分享。
使用到的SQL技术MySQL部分
查询一个库的所有表名。
结构化查询语言
从information_schema.tables中选择table_name,其中table _ schema = & # 39数据库名称& # 39;;查询数据库中所有表名和列名字段的长度。
结构化查询语言
SELECT TABLE _ NAME as & # 39表名& # 39;,列名为& # 39;列名& # 39;,COLUMN_COMMENT,DATA _ TYPE as & # 39字段类型& # 39;,COLUMN _ TYPE as & # 39长度加类型& # 39;FROM information _ SCHEMA . ` columns `其中TABLE _ SCHEMA = & # 39数据库名称& # 39;Order by table _ name,column _ name SQLserver部分SQLserver查询当前库的所有表名。
结构化查询语言
从SysObjects中选择名称,其中XType = & # 39U & # 39按名称排序;根据ID查询数据库中的重复数据
结构化查询语言
从数据库名称中选择id,其中id
结构化查询语言
-delete top(1)from database name where id = id value以删除日志。
结构化查询语言
使用[master]GOALTER DATABASE DATABASE name SET RECOVERY SIMPLE with no _ wait GOALTER DATABASE name SET RECOVERY SIMPLE-SIMPLE模式GOUSE DATABASE name GODBCC SHRINKFILE(N & # 39;数据库名称_日志& # 39;,2,truncate only)-将压缩日志大小设置为2M,可以指定数据库名称GOUSE [master]GOALTER数据库Set RECOVERY FULL with no _ wait GOALTER数据库数据库名称SET RECOVERY FULL – restore to full模式转到修改表字段。
结构化查询语言
Alter table数据库名称alter column字段名字段类型(长度)解决sqlserver问题:超时已过期。操作完成前超时已过期,或者服务器没有响应。
1.点击菜单栏:工具->选项
2.设置脚本执行超时(0根据自己的要求不限)。
3.设置链接字符串更新时间(根据自己的需要,范围是1-65535)。
Nicat Premium 16无限试用版
尝试
@echo offecho在(& # 39;中删除/f %%i的HKEY _当前_用户\软件\ PremiumSoft \ NicatPremium \注册[版本和语言]"注册查询& # 34;HKEY _当前_用户\软件\高级软件\ NicatPremium & # 34/s | findstr/L Registration & # 34;')do ( reg delete %%i /va /f)echo.echo删除(& # 39;"注册查询& # 34;HKEY _当前_用户\软件\类\ CLSID & # 34/s | findstr/E Info & # 34;')do (regdelete%% i/va/f) echo。数据迁移成功后遇到的echo finish pause问题有些表数据会出现重复,这是多次尝试迁移造成的,需要手动删除重复数据,这种情况极不可能出现,一般出现在数据量大的表中;一些表的字段类型会发生变化,迁移工具会自动转换成SqlServer支持的字段类型,从而影响一些应用服务,使其无法正常启动。开发同事需要找到它们并将其修改为正确的类型。有些表没有主键和索引,所以需要手动添加。表字段类型、索引、主键如果是一个表一个表修改的话,修改量会很大。整个迁移过程写了将近两周,比我预想的难多了,遇到的问题真的很难。不得不说,当数据量很大的时候,确实会给数据的操作带来很大的挑战。
为什么要做迁移?使用方案:使用工具:第一种迁移工具第二种迁移工具第三种迁移工具比对工具工具使用第一种迁移工具使用第二种迁移工具使用第三种迁移工具使用到的SQL技术MySQL部分sqlserver部分迁移数据成功后遇到的问题写在最后
__EOF__
免责声明:本站所有文章内容,图片,视频等均是来源于用户投稿和互联网及文摘转载整编而成,不代表本站观点,不承担相关法律责任。其著作权各归其原作者或其出版社所有。如发现本站有涉嫌抄袭侵权/违法违规的内容,侵犯到您的权益,请在线联系站长,一经查实,本站将立刻删除。