
一般来说,我们在机器学习任务中使用的每一个算法都有一个目标函数,而算法就是对这个目标函数进行优化,尤其是在分类或者回归任务中,就是用损失函数作为它的目标函数,也就是所谓的代价函数。
损失函数用于评价模型的预测值y = f (x)与真实值y的不一致性,它是非负的实函数。通常使用L(Y,f(x)),损失函数越小,模型的性能越好。
设N个样本的样本集为(X,Y)=(xi,yi),yi,i∈[1,n]为样本ii的真值,yi = f (xi),i ∈ [1,N]为样本I的预测值,f为分类或回归函数。
那么总损失函数为:
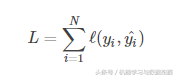

常见的损失函数(yi,yi)如下:
Zero-one Loss
零一损失是0-1损失,这是一个比较简单的损失函数。如果预测值不等于目标值,则为1,否则为0,即:
可见上述定义过于严格。如果真实值为1,预测值为0.999,那么预测应该是正确的,但是上面的定义明显判断为预测误差,所以可以改进为感知器损失。
Perceptron Loss
感知器损失就是感知的损失。即:
其中t为超参数阈值,如PLA(感知器学习算法)中取t=0.5。
Hinge Loss
铰链损失可用于解决区间最大化问题,如解决SVM的几何区间最大化问题,定义如下:
yi∈{-1,+1}
问题:SVM损失函数是如何写成铰链损失的形式的?这是面试中经常拍的。
Log Loss
(重点)最大化似然函数时,形式是连乘,但为了处理方便,通常会放上对数,这样连乘就可以转化为求和。因为对数函数是单调递增的,所以优化结果不会改变。所以log类型的损失函数也是常见的损失函数,比如在LR(Logistic回归)中使用交叉熵作为其损失函数。即:
易∈{0,1}
指定0 log = 0。
Square Loss
平方损失是平方误差,常用于回归。即:
yi,yi^∈R
Absolute Loss
绝对损失是绝对误差,常用于回归分析。即:
yi,yi^∈R
Exponential Loss
指数损失是一种指数误差,常用于boosting算法,如AdaBoost。即:
yi∈{-1,1}
正则
一般来说,在评估分类或回归模型时,需要最小化模型对训练数据的损失函数值,即使是最小化经验风险函数,但如果只考虑经验风险,就容易过拟合(详见一些防止过拟合的方法),所以还需要考虑模型的泛化能力。常用的方法是在目标函数中加入正则项。由损失项(Loss term)加上正则项(regulation term)构成结构风险(Structural risk),那么损失函数就变成:
其中λ是正则项的超参数,常用的正则化方法有L1正则化和L2正则化。详见我上一篇文章。
每个损失函数的图形如下:
免责声明:本站所有文章内容,图片,视频等均是来源于用户投稿和互联网及文摘转载整编而成,不代表本站观点,不承担相关法律责任。其著作权各归其原作者或其出版社所有。如发现本站有涉嫌抄袭侵权/违法违规的内容,侵犯到您的权益,请在线联系站长,一经查实,本站将立刻删除。